
奇富科技,为何此刻站出界说次序?这家科技公司的底气来自于那里?是否有才略为行业界说一把公认的“标尺”?
要回话这些问题,不妨先扫视行业正濒临的确切挑战。
当年三年,大模子如风暴般席卷了信贷范围,掀翻了一场以“服从翻新”为名的技能海潮。
在这过程中,迟缓变成了由互联网大厂引颈、传统银行跟进和垂直玩家深耕的三足鼎峙的花式。
跟着大模子技能的束缚,信贷行业也堕入了“精真金不怕火期”。技能上的先进性与落地效果间变成了边界。当繁密厂商纷纭标榜自身的AI才略发轫,一个根人性问题日益突显:究竟该奈何客不雅臆想,谁的技能更塌实、更的确?
近日,奇富科技给出了我方的谜底,勾通复旦大学与华南理工大学沟通东说念主员,共同发布首个面向信贷场景的多模态评测基准FCMBench-V1.0。
该基准基于确切信贷业务场景,抽象科学问题,遐想多模态评估任务与挑战,以期构建着手于业务、作事于业务的实用性评测体系。同期,奇富科技告示开源数据集与评测器具,为行业共建AI基础设施提供关节援救。
至此,骚扰纷纭的信贷AI赛说念,终于有了一把了了的“标尺”和一条公认的“基准线”,技能实力上下,终于有了可相比的刻度。
信贷AI的“无标之痛”
金融行业素有“练兵场”之称,一方面是场景下的各式需求相比复杂,所波及的历程繁密;另一方面是对数据守密性、审核合规和走动安全等主张的低容错率。
奇富科技多模态肃穆东说念主杨叶辉博士向咱们先容,“信贷审核波及几十类证件、每类证件有多种模板、审核历程波及多个样式和任务,以及多证件的交叉推理考证,用户拍摄的场景和上传的文献也多种种种。信贷场景的这些挑战关于多模态大模子的才略长短常好的试金石。”
但当信贷AI从演示考证走向深度期骗时,却遇到了一系列痛点问题。最杰出的推崇是大模子对专考场景的失焦,大模子经常更把稳通用的才略,而零落了对信贷场景的适配性。
举例,一般行业评测多聚焦于“图片识别”或“文天职类”,但信贷审核员最头疼的,并非识别“这是不是一张图片”,而是判断这张身份证与现时操作主说念主的其他材料,历史留存证件是否一致,且证件本人是否可疑。所谓的专科任务,是从数百页银行活水中识别出隐性欠债、可疑的关联方走动等,这需要深度的范围学问和复杂的推理逻辑,通用大模子时常出现失灵。
数据的合规问题,在信贷行业尤为辣手。最需要被臆想的风控模子,其西宾数据因波及用户阴私、企业交易机密,无法被分享。这导致了一个悖论,学术界无法获得高质地脱敏的确切信贷数据,沟通只可停留在真空环境下,西宾出的模子沦为“望梅止渴”。
工业界则因为数据明锐性,只可进行“黑箱竞赛”,各家均声称自家模子在特稀有据部署效果特等,却无法在第三方长入的数据集上同台竞技,不仅信任无法建立,行业也无法通过长入次序测试水平。
即便走过了模子、数据的测试,在确切分娩环境中如故会遇到很多突发和个性化的问题。举例,模子在扩充扫描PDF、高清次序照等相对次序化任务上推崇优异。但在确切宇宙中,客户上传的营业派司可能旯旮有褶皱,因年份过长可能出现磨灭;手捏身份证像片可能布景参差、晴明暗淡;汉典面审时,收集延长和视频压缩会导致语音断续、面部暧昧。这些在实验室被过滤掉的杂音,恰正是线上场景的常态,成心针对此类场景的鲁棒性测评现在严重缺失。
专考场景失焦、数据之困和鲁棒性盲区,三大痛点交汇,共同将行业推入一个负向轮回。
机构和企业选型时只可看Demo和通用打榜得益,存在一定盲目性。各家都在我方的“孤岛”上重迭竖立相似才略,并声称我方发轫,市集充斥着劣币驱逐良币的担忧。因鲁棒性在上线前得不到充分锻真金不怕火,很多神态在落地效果不足预期,插足产出比低下。
现阶段,信贷行业呈现出插足大、选型盲和考证难的窘境,大宗资源被浮滥在治理交流的基础问题上。要破损此轮回,亟需一个长入的“标尺”和一场评估范式翻新。
FCMBench,一把来自“战场”的尺子
为了治理行业的渊博性问题,奇富科技在遐想FCMBench时设定了三大中枢所在。
强调实用性,与确切信贷审核历程对皆,提供次序化评估主张。报复的是,联想情况下,若模子在该基准测试中取得邃密得益,可径直期骗于推行场景,而不单是是喜跃实验室主张。
据悉,FCMBench-V1.0构建了与确切银行审核历程高度一致的评测框架,涵盖18类中枢信贷证件,天博体育app下载如身份证、收入说明、银行活水、房产证等,包含4043张合规图像和8446个测试样本,问题障翳信贷审核全链条。
评测尽可能全面障翳通盘推行期骗场景和需求。其创新的“感知-推理-鲁棒性”三维评测体系,对信贷AI模子所需的实战中枢才略刻薄了全面的调查。
感知维度包含文档类型识别、关节信息索取、图像质地评估三大任务,考验模子从复杂图像中索取基础信息的才略;推理维度涵盖一致性校验、灵验性校验、数值狡计、合感性审核四类任务,模拟信贷员交叉考证信息、判断材料灵验性的中枢职责;鲁棒性维度则建树十类确切集结干豫,如歪斜拍摄、光照不均、反光等,测试模子在确切期骗场景中的空闲性。
在数据层面,在保证种种性的基础上,喜跃合规性条件。数据集结支捏单图像和多图像样式中的一种或多种证件,涵盖信贷审核中遇到的种种数据类型。以确切信贷材料为基础,在保证文档样式高度仿真的同期,手动生成一系列信贷筹议证件,其中通盘明锐信息均为造谣。
举座看下来,FCMBench取之于奇富科技长年的业务发挥和数据积聚,并将效坦直接用于实战场景。首个版块作念到了“言简意该”,其推出即是为了针对性地治理“无标可依”“无据可考”的AI落地痛点,让AI模子的性能评估有长入的标尺。
FCMBench并非是一个落寞的惬心,而是通盘金融行业转向实用性的信号。前年,一些大厂依然率先步履起来。
蚂蚁数科相同认可专科性和长入的次序。其构建的金融任务分类体系,包括了六大类、六十六小类场景,障翳银行、证券、保障、基金、信赖等金融全场景。此外,蚂蚁数科还勾通行业内专科机构推出Finova大模子金融期骗评测基准,深度检会智能体才略、复杂推理以及安全合规才略。
蚂蚁消金基于通义千问基座西宾“消费信贷垂类风控大模子”,将任务详备拆解为授信、审批、专项优化反诈骗和信用评估等主张。京东科技则依托供应链生态,强化票据、公约、仓单等多模态单子的结构化识别与交叉考证,针对金融语义进行了专项重构。这些操作都在一定进度上,弥补了通用大模子“专而不精”的弱势。
落实到业务上,各家的所在也高度一致,追求价值落地。非论是蚂蚁的秒级授信、京东的供应链金融快审,如故奇富科技的AI全历程审批,骨子上都是将模子性能主张滚动为,包括坏账率镌汰、客群障翳扩大、审核东说念主工资本量入为用等推行业务价值。
通过对23个主流多模态模子的全面评测,FCMBench展现出了专科的鉴识才略。在FCMBench的首轮评测中,谷歌的Gemini 3 Pro(64.61)位列交易模子榜首,阿里云Qwen3-VL-235B(57.27)成为最好的开源基模。基于奇富推行业务场景研发的信贷垂类多模态大模子,Qfin-VL-Instruct以64.92的F1分数斩获轮廓第一。
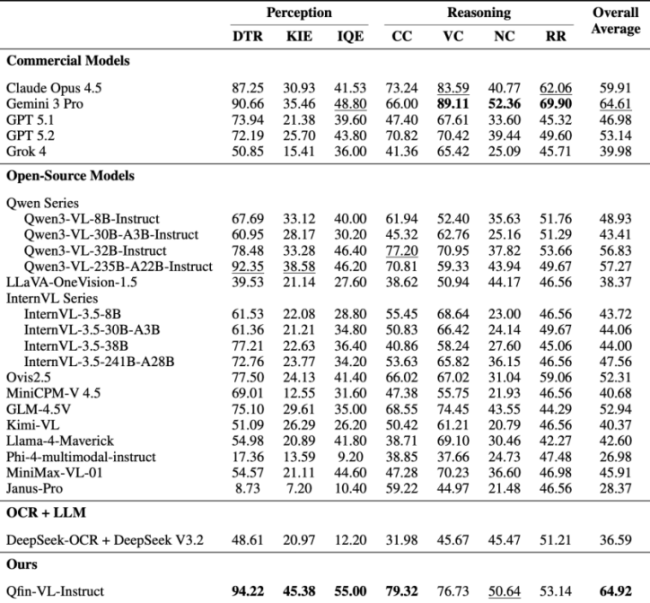
测试限度泄露,Qfin-VL-Instruct感知任务精确度行业顶尖,一致性校验才略杰出,低延长部署适配在线审批场景,是专为信贷审核优化的“场景化模子”。
其中,在感知任务维度结束全面发轫,文档类型识别、关节信息索取和图像质地评估三个子主张均高出Gemini 3 Pro。在灵验性校验、数值狡计、合感性审核等任务上,还可通过启用轻量级念念维链推理进一步松开与Gemini 3 Pro的差距。
Qfin-VL-Instruct的得益,说明了通用模子才略无法全都障翳专考场景,通过“场景数据+专科范围学问”积聚大约突破现存模子的上限,奇富科技在垂类模子上的告成,也为行业指明了一条可复制的旅途。
从“技能竞技场”到“行业共同体”
现在,奇富科技告示开源了FCMBench的数据集与评测方法,关联FCMBench的数据集、评测器具以及Qfin-VL-Instruct的试用接口已通达获得。
FCMBench的开源,象征着金融AI发展逻辑的一次根人性转向:信贷行业正从各家闭门的“黑箱竞赛”,走向基于群众次序的“生态共建”。
这一举措将透彻破损范围壁垒,推进信贷AI从“单点优化”迈向“产学研协同创新”。高质地、合规的通达数据集,让学术界领有了触及确切金融问题的“正当接口”。产学研互助得以从务虚的技能对接会,转向求实的问题攻坚,共同攻克“可解释AI”“小样本鲁棒性”“平允性考证”等既具学术深度,又攸关业务落地的真问题。
领有可量化、可复现的评测器具后,金融机构的技能评估体系得以重构。选型有筹画将从依赖厂商的“案例包装”与“榜单大比拼”,转向客不雅的才略跑分与场景适配度分析,极大镌汰有筹画风险与试错资本,并倒逼大模子厂商总结价值竞争骨子。
公开基准如团结面“照妖镜”,迫使通盘厂商在团结把“尺子”下领受锻真金不怕火。这意味着以前公说公有理,婆说婆有理的时事行将终结。当各家同拿一份考卷答题,坐在考场答题时,谁的分数更高,得益则一目了然。
金融AI的结尾并非技能炫技,而是建立剖析的信任体系。公开、透明的评测基准,正是建立这种信任的第一步。它为信贷行业畴昔建立AI模子合规认证、金融垂类范围才略测试和监管次序,都提供了灵验的念念路和实践基础。
{jz:field.toptypename/}杨叶辉博士告诉咱们,“FCMBench-V1.0只是一个开动,畴昔会捏续完善评测基准,但愿打磨好一把平允、公正,面向实战需求的尺子”。
这不单是是一次技能开源,更是一次行业共鸣的重塑。只消当技能才略可臆想、可相比、可考证时,信贷AI才能进一步走向技能期骗的深水区,推进通盘行业走向更安全、可靠、可控的智能化畴昔。
 备案号:
备案号: